Summary:
NVIDIA's latest language model, Llama-3.1-Nemotron-51B, revolutionizes AI with groundbreaking neural architecture search (NAS) techniques. This model delivers a perfect blend of efficiency and accuracy, pushing AI development to new heights. With its ability to reduce memory load while maintaining performance, it offers a significant advantage for tech companies seeking cost-effective, scalable solutions.
How Neural Architecture Search is Changing the AI Game
The realm of artificial intelligence is evolving faster than ever, and one term is becoming increasingly pivotal—neural architecture search.
Traditionally, building AI models required massive computational resources, yet even the most complex models often fell short in terms of efficiency.
Neural architecture search, or NAS, is a technique that has dramatically changed this landscape, allowing AI developers to craft highly optimized architectures tailored for specific tasks.
NVIDIA’s latest innovation, the Llama-3.1-Nemotron-51B, is a perfect example of NAS's impact.
This model, derived from Meta’s Llama-3.1-70B, promises to advance AI capabilities in ways that will reshape the tech industry.
By using NAS to design a neural network with enhanced accuracy and reduced computational demands, this model can run more efficiently on a single NVIDIA H100 GPU while maintaining nearly the same level of precision as larger models.
What is Neural Architecture Search?
Neural architecture search (NAS) refers to a set of algorithms used to automate the design of artificial neural networks.
In other words, NAS helps AI engineers determine the best configuration for a model by exploring various design options.
These algorithms can optimize a network's layers, blocks, and connections, ultimately leading to improved performance and efficiency. It’s like giving AI the ability to build its own architecture based on the goals it needs to accomplish.
With Llama-3.1-Nemotron-51B, NAS played a key role in reducing the model's memory footprint and computational requirements, allowing for greater flexibility in deployment.
It brings a new frontier to AI model development—one that’s not just focused on raw power but smart, efficient design.
The Role of Efficiency in AI Development
In the fast-paced world of AI, efficiency often takes a back seat to accuracy and scale.
However, as AI systems grow more complex and businesses seek to deploy these models in real-world scenarios, the cost of inference—how much computational power is required to generate results—becomes critical.
Neural architecture search offers a solution to this challenge.
For companies that rely on large language models (LLMs) like Llama-3.1-Nemotron-51B, improving efficiency directly translates into reduced operational costs.
This means companies can handle larger workloads on fewer resources, such as GPUs, while maintaining high levels of accuracy.
Transitioning from traditional methods to NAS-generated models enables businesses to harness cutting-edge AI capabilities without the excessive costs and energy usage typically associated with large models.
This not only makes AI more accessible but also more scalable, particularly for businesses looking to deploy AI across cloud infrastructures or edge systems.
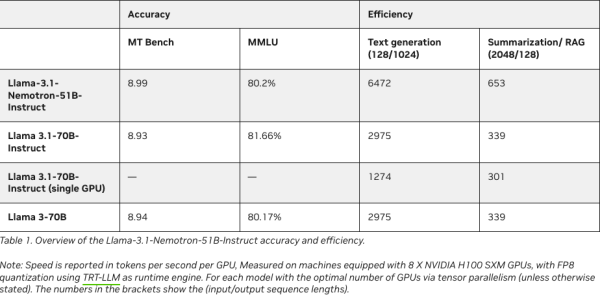
Llama-3.1-Nemotron-51B: Setting a New Benchmark in AI Performance
Llama-3.1-Nemotron-51B is designed to push the boundaries of what AI can achieve.
While Meta's Llama-3.1-70B served as the reference model, NVIDIA’s innovation, powered by neural architecture search, optimizes its architecture to achieve greater throughput and workload efficiency.
In fact, Llama-3.1-Nemotron-51B offers 2.2x faster inference speeds compared to its predecessor, all while reducing memory consumption.
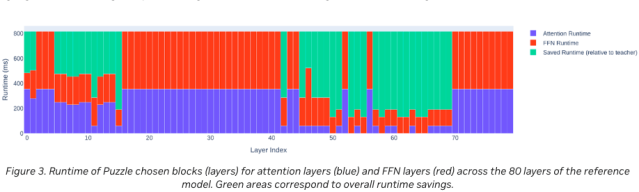
This model's remarkable efficiency stems from significant architectural adjustments made possible through NAS.
Unlike traditional models that often rely on repeated, identical blocks, the Nemotron model employs an irregular block structure where certain layers are pruned or optimized.
This irregularity allows for more efficient computation without sacrificing performance, making the model both faster and lighter.
Key Performance Metrics:
- 2.2x Faster Inference: Compared to Llama-3.1-70B, the Nemotron model performs nearly twice as fast.
- 4x Larger Workload on a Single GPU: The model's reduced memory footprint allows it to process larger workloads with fewer resources.
- 98%+ Accuracy Preservation: Despite its optimized design, the model retains over 98% of the accuracy of the original reference model.
Optimizing Accuracy Per Dollar: Why Efficiency Matters in AI
One of the greatest barriers to adopting large language models is the cost of inference.
Running high-performance models like Llama-3.1-70B requires substantial computational resources, and in business contexts, this can quickly become expensive.
However, with the introduction of Llama-3.1-Nemotron-51B, NVIDIA provides a solution that balances performance and cost-effectiveness.
By leveraging neural architecture search, the Nemotron model achieves a significant reduction in FLOPs (floating-point operations per second) while maintaining exceptional accuracy.
This optimization makes it possible to run the model on a single NVIDIA H100 GPU, drastically cutting the cost per inference task.
Moreover, its compatibility with TensorRT-LLM engines ensures that businesses can deploy this model at scale, whether in cloud environments, data centers, or even edge systems.
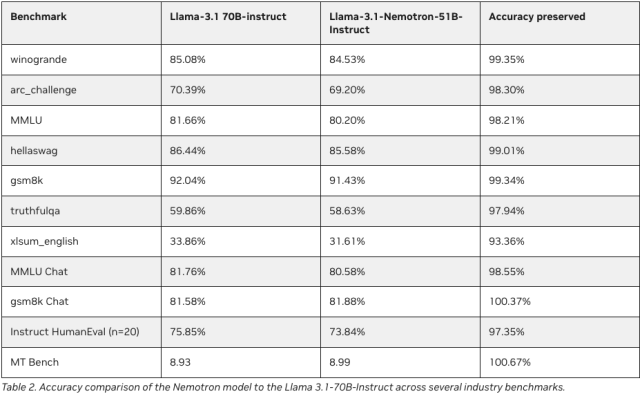
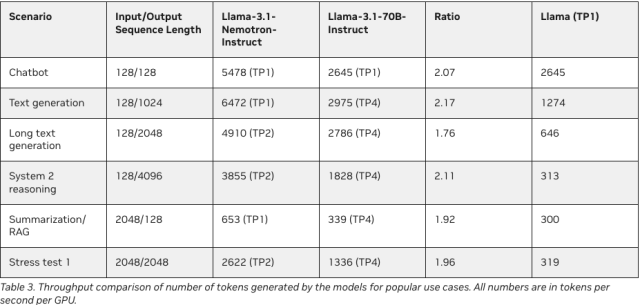
For companies that depend on AI for mission-critical tasks, having a model that strikes the right balance between accuracy and efficiency can be the difference between success and failure.
As AI continues to evolve, the ability to maximize output while minimizing cost will be a key factor in model selection.
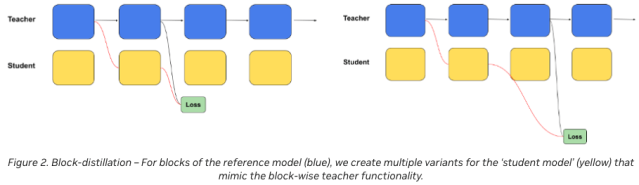
How Neural Architecture Search Drives Innovation in Model Design
Neural architecture search doesn’t just create more efficient models; it redefines the way we think about AI design.
In traditional AI development, models are often constructed with repeated layers, which can be inefficient when scaled up.
With NAS, NVIDIA has developed a system that tailors each layer to the specific needs of the model.
For instance, in the Llama-3.1-Nemotron-51B, some transformer layers have been pruned or replaced entirely.
This approach allows for more focused computational power where it's needed most, enhancing both speed and accuracy.
The use of NAS also enables NVIDIA to fine-tune the model for specific hardware configurations, such as the H100 GPU, ensuring that the architecture is optimized for real-world deployment scenarios.
This capability to design customized neural networks on the fly opens new doors for AI developers, offering more flexibility in how they deploy large language models across various platforms.
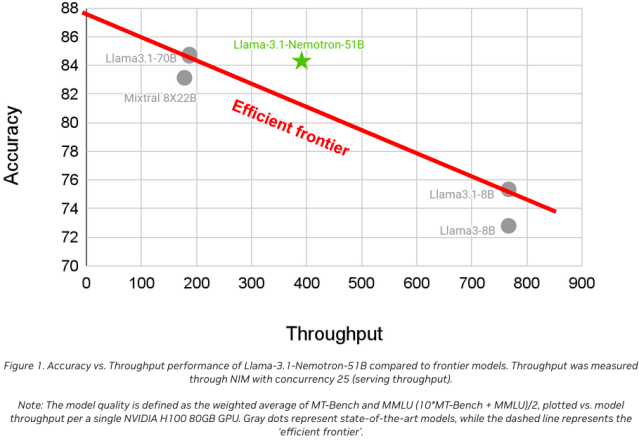
Breaking the Efficient Frontier: A New Era of AI Performance
NVIDIA’s Llama-3.1-Nemotron-51B isn’t just another language model; it represents a leap forward in AI performance.
With its NAS-driven architecture, the model breaks through what experts call the "efficient frontier"—the point at which no further gains in efficiency can be made without sacrificing accuracy.
By advancing beyond this frontier, the Nemotron model offers a new paradigm in AI: models that are not only accurate but also scalable, cost-effective, and deployable on a wide range of systems.
Conclusion: The Future of AI Lies in Neural Architecture Search
As we move forward in the development of AI, neural architecture search will continue to play a pivotal role in shaping the future.
NVIDIA’s Llama-3.1-Nemotron-51B is a shining example of how NAS can be used to create models that are both highly accurate and incredibly efficient.
For businesses and tech experts alike, the message is clear: the future of AI lies in smart, efficient design.
By adopting models like Llama-3.1-Nemotron-51B, companies can reduce costs, streamline deployment, and unlock new possibilities for AI-driven innovation.
As neural architecture search continues to evolve, we can only imagine what breakthroughs lie ahead.